
Big Data is nothing but the data arriving at a very high speed and uncontrollable rate. Merely speaking the amount of data in Big Data comprises of more complications and larger datasets, mainly from the latest data sources. Such an enormous and voluminous package is difficult to process by the traditional data processing software. The massive amount can be used to tackle business problems, that you haven’t faced before.
Let’s relate data with the trio of Vs and see how it is valued as per these traits.
The Trio Vs of Big Data
#Volume
The chunk of data does matter. The high volumes of cheap density, unstructured data is tackled using Big Data. The data consists of unknown values coming from big trunks of social media, sensor-enabled equipment. Ranges from terabytes to petabytes depending on the company.
#Velocity
Only one thing that is sky bursting is data and that too at high velocity. Generally, the highest velocity rate data goes directly into memory rather than writing to hard disks. Few internet-enabled agile products behave in real time and so do need real-time evaluation and business.
#Variety
The data is humungous and even a lot more diverse. Two types of data exist so far. The structured data easily fits in relational databases, but the unstructured data needs the brainstorming. The steep slope of Big Data brings in the unstructured data utmost.
The story does not end here, the inclusion of semi-structured data also gets added to the debris such as text, video, audio needs support of metadata with a pinch of pre-processing.
Now let me acknowledge you about Bid Data’s most widely used framework Hadoop that efficiently sorts data complexity making it easy for humans to manage the everyday growing heaps of data.
The Big Data Frameworks
Apache was developed and maintained by Apache Software Foundation which is the web server software who has developed numerous tools to handle the database too. They even have the liability of Big Data tools. Some of the Big Data frameworks are listed below:
- Apache Hadoop
- Azure HDInsight (Microsoft)
- NoSQL (MongoDB)
- Hive
- Sqoop
- PolyBase
- Excel
- Presto
- Hadoop
Hadoop in every firm’s and online schools’ is more beaking. The humungous data is dealt with Hadoop due to its marvelous features.
Hadoop software library is such a framework which allows its users to have the provision of distributed processing of big data sets using easy programming models across clusters of machines.
Hadoop is designed in such a manner that it can be scaled up from a simple coding machine to thousands of computers, with each leveraging local computation and store units. It deals with detection and handling failures at the application layer, instead of depending on hardware to provide high availability.
Professionals thinking to expand their knowledge about data can look upon a Big Data Hadoop Certification Training Course that will help them develop their skills and boost their career. The wingspread aura of Information Technology can be well handled after studying and knowing the ever-growing data.
#The Robust Hadoop Features
Here are some features of Hadoop that are worth reading. Take a look:
- Flexibility – The zeal is involved in establishing an environment where both structured as well as unstructured data can be handled wisely. All of the challenges so far faced are tackled beautifully by the framework. This also accounts for a pretty decision-making process from unstructured data.
- Scalability – The provision of open source platform, plus IT standard hardware running makes it highly scalable. The new nodes can be inserted as it is in the system and data volume of processing requirements grow without changing anything in the existing programs
- Fault Tolerance – The data is stored in HDFS where data easily gets replicated at two different locations. So even one of the duo collapses we have the rescue. This terms it high fault tolerance.
- Faster Data Processing – The pipeline of data processing in Hadoop is mind-blowingly designed. It is extremely good at processing the high-volume batch just due to the ability of parallel processing. Hadoop can process 10 times at more speed than its competitors on a single thread server.
- Robustness – The ecosystem of the demon is so robust that it is easily suited to meet the analytical jobs of developers and tiny and tidy to large blocks. The ecosystem arrives with a suite of tools and technologies to deliver a highly diverse data processing feeds.
- Cost Effective – Hadoop saves a lot of cost due to its parallel computing ability to accommodate the servers, which results in the highly reduced cost per terabyte, which obviously makes it the white gold model for your whole data.
#Hadoop Modules to Encounter
Hadoop Common – One man army, responsible for all activities occurring in the wireframe, that supports other Hadoop modules.
HDFS (Hadoop Distributed File System) – provides high throughput access to application data.
Hadoop Yarn – Job scheduling and cluster resource management can be done in this framework.
Hadoop MapReduce – To process the enormous data sets parallelly, is Yarn based system.
Hadoop Ozone – Object store
The Working Architecture of Big Data Hadoop
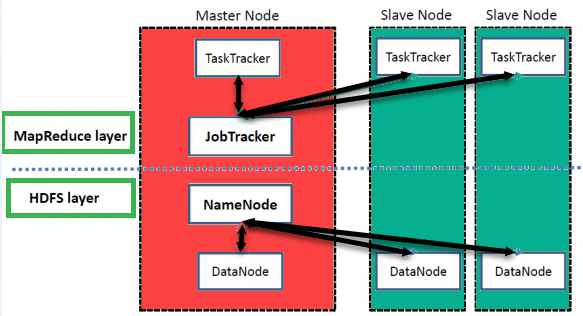
Hadoop follows the HDFS file system which has a master-slave architecture and distributed data processing using Map reduction along with some file system methods.
NameNode: This is namecode that is used to designate every file and directory of the namespace.
DataNode: The state of HDFS node is managed by this node, addition of interaction with the blocks
MasterNode: Parallel processing ability is what this node ables a user making use of MapReduce
SlaveNode: In order to perform the complex calculations, the Hadoop cluster provides some additional machines; All the slave nodes come with Task Tracker + DataNode. This thing has the allowance to synch the processes with NameNode and Job Tracker respectively.
Hadoop: Sight of its Application
Some of the areas where Hadoop has firmed its feet are:
Big Data, Predictive Analysis, Machine Learning, data mining, data warehousing, Healthcare where it plays a crucial role in data wrangling and manipulating.
Now take a rundown below how Big Data’s Hadoop has made its contribution in smoothening the data process to make the best use of it.
Social Media Data
The unique capability of grabbing the data and to imply analysis on sentiment data is what Hadoop gives us the aurora of sentiment analysis to some extent at least. The sentiment data is the unstructured data which one posts in the form of opinions, attitudes, feelings or pictures on various social applications, also include the product reviews and customer support interactions.
Click Stream Data
How would you know what a visitor looked and valued on your website? The Hadoop stores and processes the huge chunks of click stream data. Some of them are:
- The origin of the visitor before reaching to a special site
- The keyword searched to reach the site
- The first web page opened
- The interested other web pages of the visitor
- Time spent the person on each page
- The when and where bounce backing of a visitor
- The final purchase by the visitor
In actual it’s the analysis of website performance and user engagement. By adopting Hadoop, each one can work on click stream analysis. On top of it, Hadoop also makes beneficial use of Apache HIVE to interact with millions and trillions of data rows.
Security and Compliance
Hadoop uses the report of analysis of server-log data, and the response is given in no time to firm’s security breach. The admin has the opportunity now to log into the server logs directly using Hadoop to identify the root cause of the security breach and hence can repair it.
Hadoop also has dived into geo-location tracking, Machine, and Sensor Data.
The Essence
All the above said Hadoop has rock-solid feet in every industry. Huge investments are being made by the giants. If data is what hovers every second in your skull, then the knowledge of Big Data + Hadoop is a must for a developer.


