What is Data Science?
Data science is that the study of wherever data comes from, what it represents and the way it is changed into a valuable resource within the creation of business and IT methods. Data science is a multidisciplinary blend of data inference, algorithm development, and technology in order to solve analytically complex problems. Data Science is the combination of statistics, mathematics, programming, problem solving, capturing data in ingenious ways, the ability to look at things differently, and the activity of cleansing, preparing and aligning the data.
What are the major Skills Data Scientist need?
A data scientist analyzes data to learn about scientific processes. Some different job titles in data science include data analyst, data engineer, computer and information research scientist, computer systems analyst, and operations research analyst.
- Skills in Analytics and computer science or different area
- Mathematics skills
- SAS or R analytics tool skills
- Programming Coding: Python Coding, Java, Perl, C, C++
- SQL Database/Coding
- Hadoop Platform
- Unstructured data
- Product intuition
- Intellectual curiosity
- Business acumen
- Technology and Hacking skills
- Good Communication skills
What is Data Scientist?
A data scientist is a professional responsible for collecting, analyzing and interpreting large amounts of data to identify ways to help a business improve operations and gain a competitive edge over rivals.
Can you explain Data Munging or Data wrangling?
Raw data are often unstructured and messy, with info returning from disparate data sources, mismatched or missing records, and a slew of different tough problems. Data munging is a term to describe the data wrangling to bring together data into cohesive views, as well as the janitorial work of cleaning up data so that it is polished and ready for downstream usage. (The term is thought to have originated as a backronym for “Mash Until No Good”).
Why is Data Munging useful?
Often ‘raw’ data can be hard, even impossible, to analyses and gain useful insights from. This is where somebody will transform the data entries, fields, rows and columns into a more useful format. Activities to achieve this might include:
- Cleansing
- Joining/Matching
- Filtering
- Standardizing
- Consolidating
Can you explain Data Mining?
Data Mining (Data Recovery or Knowledge Discovery) is the process of sorting through large data sets to identify patterns and establish relationships to solve problems through data analysis. Data mining tools allow enterprises to predict future trends. which is collected and assembled in common areas, such as data warehouses, for efficient analysis, data mining algorithms, facilitating business decision making and other information requirements to ultimately cut costs and increase revenue.
The benefits of data mining come from the ability to uncover hidden patterns and relationships in data that can be used to make predictions that impact businesses.
Main features of data mining are:
- Automatic pattern predictions based on trend and behavior analysis.
- Creation of decision-oriented information.
- Prediction based on likely outcomes.
- Focus on large data sets and databases for analysis.
- Clustering based on finding and visually documented groups of facts not previously known.
Read : Data Analyst Interview Questions and Answers
Can you explain Data Preparation?
Data preparation (Data Preprocessing) in this context means manipulation of data into a form suitable for further analysis and processing. It is a process that involves many different tasks and which cannot be fully automated. Many of the data preparation activities are routine, tedious, and time consuming. It has been estimated that data preparation accounts for 60%-80% of the time spent on a data mining project.
Data Preparation is necessary is when a business intelligence platform needs source data to be adapted and transformed to meet the needs of data mining and data visualization tools. The benefits of Data preparation, High-quality data is essential to business intelligence efforts and other types of data analytics, as well as better overall operational efficiency.
Can you define Data Discretization?
Dataset usually contains 3 types of attributes- continuous, nominal and ordinal. Some algorithms accept only categorical attributes. Data discretization step helps data scientist divide continuous attributes into intervals and also helps reduce the data size – preparing it for analysis.
Can you define Data Reduction?
Data reduction is the process of minimizing the amount of data that needs to be stored in a data storage environment. Data reduction can increase storage efficiency and reduce costs. Data warehouse might contain petabytes of data and running analysis on the complete data present in the warehouse, could be a time-consuming process.
In this step data scientists obtain a reduced representation of the data set that is smaller in size but yields almost same analysis outcomes. There are various data reduction strategies a data scientist can apply, based on the requirement- dimensionality reduction, data cube aggregation and numerosity reduction.
Can you define Analytics?
Analytics has risen quickly in popular business lingo over the past several years; the term is used loosely, but generally meant to describe critical thinking that is quantitative in nature. Technically, analytics is the “science of analysis” put another way, the practice of analyzing information to make decisions.
What is the difference between an analyst and a data scientist?
Data Analyst: This can mean a lot of things. Common thread is that analysts look at data to try to gain insights. Analysts may interact with data at both the database level and the summarized report level.
Data Scientist: Specialty role with abilities in math, technology, and business acumen. Data scientists work at the raw database level to derive insights and build data product.
Can you define Feature vector?
Feature vector is an n-dimensional vector of numerical features that represent some object. Many algorithms in machine learning require a numerical representation of objects, since such representations facilitate processing and statistical analysis. When representing images, the feature values might correspond to the pixels of an image, while when representing texts, the features might be the frequencies of occurrence of textual terms.
How do Data Scientists use Statistics?
Statistics helps Data Scientists to look into the data for patterns, hidden insights and convert Big Data into Big insights. It helps to get a better idea of what the customers are expecting. Data Scientists can learn about the consumer behavior, interest, engagement, retention and finally conversion all through the power of insightful statistics.
It helps them to build powerful data models in order to validate certain inferences and predictions. All this can be converted into a powerful business proposition by giving users what they want at precisely when they want it.
Can you explain Recommender System?
A recommender system is today widely deployed in multiple fields like movie recommendations, music preferences, social tags, research articles, and search queries and so on. The recommender systems work as per collaborative and content-based filtering or by deploying a personality-based approach. This type of system works based on a person’s past behavior in order to build a model for the future.
This will predict the future product buying, movie viewing or book reading by people. It also creates a filtering approach using the discrete characteristics of items while recommending additional items.
Can you explain Collaborative filtering?
The process of filtering used by most of the recommender systems to find patterns or information by collaborating viewpoints, various data sources and multiple agents.
An example of collaborative filtering can be to predict the rating of a particular user based on his/her ratings for other movies and others’ ratings for all movies. This concept is widely used in recommending movies in IMDB, Netflix & BookMyShow, product recommenders in e-commerce sites like Amazon, eBay & Flipkart, YouTube video recommendations and game recommendations in Xbox.
What is difference between SAS, R and Python programming?
SAS Analytics: SAS is the most widely used analytics tools used by some of the biggest companies on different countries. It has some of the best statistical functions, graphical user interface, but can come with a price tag and hence it cannot be readily adopted by smaller enterprises
R Programming: The best part about R is that it is an Open Source tool and hence used generously by academia and the research community. It is a robust tool for statistical computation, graphical representation and reporting. Due to its open source nature it is always being updated with the latest features and then readily available to everybody.
Python Programming: Python is a powerful open source programming language that is easy to learn, works well with most other tools and technologies. The best part about Python is that it has innumerable libraries and community created modules making it very robust. It has functions for statistical operation, model building and more.
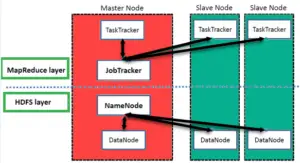
What are the two main components of the Hadoop Framework?
HDFS and YARN are basically the two major components of Hadoop framework.
HDFS (Hadoop Distributed File System): It is the distributed database working on top of Hadoop. It is capable of storing and retrieving bulk of datasets in no time.
YARN (Yet Another Resource Negotiator): It allocates resources dynamically and handles the workloads.
Read :Machine Learning Interview Questions and Answers
Which one would you prefer for text analytics Python or R?
The best possible answer for this would be Python because it has Pandas library that provides easy to use data structures and high-performance data analysis tools.
Can you explain Data Cleansing?
Data cleansing (Data Cleaning or Data Scrubbing) is the process of altering data in a given storage resource to make sure that it is accurate and correct. There are many ways to pursue data cleansing in various software and data storage architectures; most of them center on the careful review of data sets and the protocols associated with any particular data storage technology.
Data cleansing in Data Quality Services (DQS) includes a computer-assisted process that analyzes how data conforms to the knowledge in a knowledge base, and an interactive process that enables the data steward to review and modify computer-assisted process results to ensure that the data cleansing is exactly as they want to be done.
Can you define Cluster Sampling?
Cluster sampling is a technique used when it becomes difficult to study the target population spread across a wide area and simple random sampling cannot be applied. Cluster Sample is a probability sample where each sampling unit is a collection or cluster of elements.
Can you explain Interpolation and Extrapolation?
The terms of interpolation and extrapolation are extremely important in any statistical analysis. Extrapolation is the determination or estimation using a known set of values or facts by extending it and taking it to an area or region that is unknown. It is the technique of inferring something using data that is available.
Interpolation on the other hand is the method of determining a certain value which falls between a certain set of values and the sequence of values. This is especially useful when you have data at the two extremities of a certain region but you don’t have enough data points at the specific point. This is when you deploy interpolation to determine the value that you need.
Can you define Linear Regression?
Linear regression is a statistical technique where the score of a variable Y is predicted from the score of a second variable X. X is referred to as the predictor variable and Y as the criterion variable.
Can you explain Supervised Learning?
Supervised learning is the machine learning task of inferring a function from labeled training data. The training data consist of a set of training examples.
Algorithms: Support Vector Machines, Regression, Naive Bayes, Decision Trees, K-nearest Neighbor Algorithm and Neural Networks
Can you explain unsupervised learning?
Unsupervised learning is a type of machine learning algorithm used to draw inferences from datasets consisting of input data without labeled responses.
Algorithms: Clustering, Anomaly Detection, Neural Networks and Latent Variable Models
Can you explain Eigenvalue and Eigenvector?
Eigenvectors are used for understanding linear transformations. In data analysis, we usually calculate the eigenvectors for a correlation or covariance matrix. Eigenvectors are the directions along which a particular linear transformation acts by flipping, compressing or stretching. Eigenvalue can be referred to as the strength of the transformation in the direction of eigenvector or the factor by which the compression occurs.
Can you define A/B Testing?
A/B testing (sometimes called split testing or bucket testing) is comparing two versions of a web page to see which one performs better. You compare two web pages by showing the two variants (let’s call them A and B) to similar visitors at the same time.
The one that gives a better conversion rate, wins! AB testing is essentially an experiment where two or more variants of a page are shown to users at random, and statistical analysis is used to determine which variation performs better for a given conversion goal.
Can you explain Systematic Sampling?
Systematic sampling is a statistical technique where elements are selected from an ordered sampling frame. In systematic sampling, the list is progressed in a circular manner so once you reach the end of the list, it is progressed from the top again. The best example of systematic sampling is equal probability method.
Can you define power Analysis?
Power analysis is a major role of experimental design. It allows us to determine the sample size required to detect an effect of a given size with a given degree of confidence. Conversely, it allows us to determine the probability of detecting an effect of a given size with a given level of confidence, under sample size constraints. If the probability is unacceptably low, we would be wise to alter or abandon the experiment.
It is the procedure that researchers can use to determine if the test contains enough power to make a reasonable conclusion. From another perspective power analysis can also be used to calculate the number of samples required to achieve a specified level of power.
How can you assess a good logistic model?
There are various methods to assess the results of a logistic regression analysis-
- Using Classification Matrix to look at the true negatives and false positives.
- Concordance that helps identify the ability of the logistic model to differentiate between the event happening and not happening.
- Lift helps assess the logistic model by comparing it with random selection.
Explain while working on a data set, how do you select important variables?
Following are the methods of variable selection you can use:
- Remove the correlated variables prior to selecting important variables
- Use linear regression and select variables based on p values
- Use Forward Selection, Backward Selection, Stepwise Selection
- Use Random Forest, Xgboost and plot variable importance chart
- Use Lasso Regression
- Measure information gain for the available set of features and select top n features accordingly.
What is the advantage of performing dimensionality reduction before fitting an SVM?
Support Vector Machine Learning Algorithm performs better in the reduced space. It is beneficial to perform dimensionality reduction before fitting an SVM if the number of features is large when compared to the number of observations.
What is the differences between univariate, bivariate and multivariate analysis?
These are descriptive statistical analysis techniques which can be differentiated based on the number of variables involved at a given point of time. For example, the pie charts of sales based on territory involve only one variable and can be referred to as univariate analysis.
If the analysis attempts to understand the difference between 2 variables at time as in a scatterplot, then it is referred to as bivariate analysis. For example, analyzing the volume of sale and a spending can be considered as an example of bivariate analysis.
Analysis that deals with the study of more than two variables to understand the effect of variables on the responses is referred to as multivariate analysis.
When is Ridge regression favorable over Lasso regression?
You can quote ISLR’s authors Hastie, Tibshirani WHO declared that, in presence of few variables with medium / massive sized impact, use lasso regression. In presence of many variables with small / medium sized effect, use ridge regression.
Conceptually, we can say, lasso regression (L1) does both variable selection and parameter shrinkage, whereas Ridge regression only does parameter shrinkage and end up including all the coefficients in the model. In presence of correlated variables, ridge regression might be the preferred choice. Also, ridge regression works best in situations where the least square estimates have higher variance. Therefore, it depends on our model objective.
What are various steps involved in an analytics project?
- First, understand the business problem
- Explore the data and become familiar with it.
- Prepare the data for modelling by detecting outliers, treating missing values, transforming variables, etc.
- After data preparation, start running the model, analyses the result and tweak the approach. This is an iterative step till the best possible outcome is achieved.
- Validate the model using a new data set.
- Start implementing the model and track the result to analyze the performance of the model over the period of time.
How do you understand by Bias Variance trade off?
The error emerging from any model can be broken down into three components mathematically. Following are these component:Bias error is useful to quantify how much on an average are the predicted values different from the actual value.
A high bias error means we have a under-performing model which keeps on missing important trends. Variance on the other side quantifies how are the prediction made on same observation different from each other. A high variance model will over-fit on your training population and perform badly on any observation beyond training.
How would you evaluate a logistic regression model? I know that a linear regression model is generally evaluated using Adjusted R² or F value.
We can use the following methods:
- Since logistic regression is used to predict probabilities, we can use AUC-ROC curve along with confusion matrix to determine its performance.
- Also, the analogous metric of adjusted R² in logistic regression is AIC. AIC is the measure of fit which penalizes model for the number of model coefficients. Therefore, we always prefer model with minimum AIC value.
- Null Deviance indicates the response predicted by a model with nothing but an intercept. Lower the value, better the model. Residual deviance indicates the response predicted by a model on adding independent variables. Lower the value, better the model
How do you treat missing values during analysis?
- The extent of the missing values is identified after identifying the variables with missing values. If any patterns are identified the analyst has to concentrate on them as it could lead to interesting and meaningful business insights.
- If there are no patterns identified, then the missing values can be substituted with mean or median values (imputation) or they can simply be ignored. Assigning a default value which can be mean, minimum or maximum value. Getting into the data is important.
- If it is a categorical variable, the default value is assigned. The missing value is assigned a default value. If you have a distribution of data coming, for normal distribution give the mean value.
- If 80% of the values for a variable are missing then you can answer that you would be dropping the variable instead of treating the missing values.
Can you explain root cause analysis?
Root cause analysis was initially developed to analyze industrial accidents but is now widely used in other areas. It is a problem-solving technique used for isolating the root causes of faults or problems. A factor is called a root cause if its deduction from the problem-fault-sequence averts the final undesirable event from reoccurring.
Can you use machine learning for time series analysis?
Yes, it can be used but it depends on the applications.
Can you write the formula to calculate R-square?
R-Square can be calculated using the below formular –
(Residual Sum of Squares/ Total Sum of Squares)
Can you explain difference between Data modeling and Database design?
Data Modeling: It can be considered as the first step towards the design of a database. Data modeling creates a conceptual model based on the relationship between various data models. The process involves moving from the conceptual stage to the logical model to the physical schema. It involves the systematic method of applying the data modeling techniques.
Database Design: This is the process of designing the database. The database design creates an output which is a detailed data model of the database. Strictly speaking database design includes the detailed logical model of a database but it can also include physical design choices and storage parameters.
What is the difference between Bayesian Estimate and Maximum Likelihood Estimation (MLE)?
In Bayesian estimate we have some knowledge about the data/problem (prior). There may be several values of the parameters which explain data and hence we can look for multiple parameters like 5 gammas and 5 lambdas that do this. As a result of Bayesian Estimate, we get multiple models for making multiple predictions i.e. one for each pair of parameters but with the same prior.
So, if a new example need to be predicted than computing the weighted sum of these predictions serves the purpose.Maximum likelihood does not take prior into consideration (ignores the prior) so it is like being a Bayesian while using some kind of a flat prior.
Can you explain K-Mean?
K-means is one of the simplest unsupervised learning algorithms that solve the well-known clustering problem. K-means clustering is a type of unsupervised learning, which is used when you have unlabeled data (data without defined categories or groups).
The goal of this algorithm is to find groups in the data, with the number of groups represented by the variable K. The algorithm works iteratively to assign each data point to one of K groups based on the features that are provided. Data points are clustered based on feature similarity.
In k-means or kNN, we use euclidean distance to calculate the distance between nearest neighbors. Why not manhattan distance?
We don’t use manhattan distance because it calculates distance horizontally or vertically only. It has dimension restrictions. On the other hand, euclidean metric can be used in any space to calculate distance. Since, the data points can be present in any dimension, euclidean distance is a more viable option.
For Example: Think of a chess board, the movement made by a bishop or a rook is calculated by manhattan distance because of their respective vertical & horizontal movements
Can you define Convex Hull?
The Convex Hull is the line completely enclosing a set of points in a plane so that there are no concavities in the line. More formally, we can describe it as the smallest convex polygon which encloses a set of points such that each point in the set lies within the polygon or on its perimeter.
Can you explain the difference between a Test Set and a Validation Set?
Validation set can be considered as a part of the training set as it is used for parameter selection and to avoid Overfitting of the model being built. On the other hand, test set is used for testing or evaluating the performance of a trained machine leaning model.
What do you understand by Type I vs Type II error?
Type I error is committed when the null hypothesis is true and we reject it, also known as a ‘False Positive’. Type II error is committed when the null hypothesis is false and we accept it, also known as ‘False Negative’.
In the context of confusion matrix, we can say Type I error occurs when we classify a value as positive (1) when it is actually negative (0). Type II error occurs when we classify a value as negative (0) when it is actually positive (1).
Why is resampling done?
Resampling is done in any of these cases:
- Estimating the accuracy of sample statistics by using subsets of accessible data or drawing randomly with replacement from a set of data points
- Substituting labels on data points when performing significance tests
- Validating models by using random subsets (bootstrapping, cross validation)
What cross validation technique would you use on time series data set? Is it k-fold or LOOCV?
Cross-validation is primarily a way of measuring the predictive performance of a statistical model. Every statistician knows that the model fit statistics are not a good guide to how well a model will predict: high R2 does not necessarily mean a good model. It is easy to over-fit the data by including too many degrees of freedom and so inflate R2 and other fit statistics.
Neither, in time series problem, k fold can be troublesome because there might be some pattern in year 4 or 5 which is not in year 3. Resampling the data set will separate these trends, and we might end up validation on past years, which is incorrect. Instead, we can use forward chaining strategy with 5 fold as shown below:
Fold 1: training [1], test [2]
Fold 2: training [1 2], test [3]
Fold 3: training [1 2 3], test [4]
Fold 4: training [1 2 3 4], test [5]
Fold 5: training [1 2 3 4 5], test [6]
Where 1, 2, 3,4,5,6 represents “year”.
How is True Positive Rate and Recall related? Write the equation.
True Positive Rate = Recall. Yes, they are equal having the formula (TP/TP + FN).
Can you explain cross-validation?
It is a model validation technique for evaluating how the outcomes of a statistical analysis will generalize to an independent data set. It is mainly used in backgrounds where the objective is forecast and one wants to estimate how accurately a model will accomplish in practice. The goal of cross-validation is to term a data set to test the model in the training phase (i.e. validation data set) in order to limit problems like overfitting, and gain insight on how the model will generalize to an independent data set.
What are the various aspects of a Machine Learning process?
Domain knowledge: This is the first step wherein we need to understand how to extract the various features from the data and learn more about the data that we are dealing with. It has got more to do with the type of domain that we are dealing with and familiarizing the system to learn more about it.
Feature Selection: This step has got more to do with the feature that we are selecting from the set of features that we have. Sometimes it happens that there are a lot of features and we have to make an intelligent decision regarding the type of feature that we want to select to go ahead with our machine learning endeavor.
Algorithm: This is a vital step since the algorithms that we choose will have a very major impact on the entire process of machine learning. You can choose between the linear and nonlinear algorithm. Some of the algorithms used are Support Vector Machines, Decision Trees, Naïve Bayes, K-Means Clustering, etc.
Training: This is the most important part of the machine learning technique and this is where it differs from the traditional programming. The training is done based on the data that we have and providing more real-world experiences. With each consequent training step, the machine gets better and smarter and able to take improved decisions.
Evaluation: In this step we actually evaluate the decisions taken by the machine in order to decide whether it is up to the mark or not. There are various metrics that are involved in this process and we have to closed deploy each of these to decide on the efficacy of the whole machine learning endeavor.
Optimization: This process involves improving the performance of the machine learning process using various optimization techniques. Optimization of machine learning is one of the most vital components wherein the performance of the algorithm is vastly improved. The best part of optimization techniques is that machine learning is not just a consumer of optimization techniques but it also provides new ideas for optimization too.
Testing: Here various tests are carried out and some these are unseen set of test cases. The data is partitioned into test and training set. There are various testing techniques like cross-validation in order to deal with multiple situations.
What are the Applications of Data Science?
Digital Advertisements: The entire digital marketing spectrum uses the data science algorithms – from display banners to digital billboards. This is the mean reason for digital ads getting higher CTR than traditional advertisements.
Internet search: Search engines make use of data science algorithms to deliver best results for search queries in a fraction of seconds.
Recommender systems: The recommender systems not only make it easy to find relevant products from billions of products available but also adds a lot to user-experience. A lot of companies use this system to promote their products and suggestions in accordance to the user’s demands and relevance of information. The recommendations are based on the user’s previous search results.
What is the difference between Data science, Machine Learning and Artificial intelligence?
Data Science: It is an interdisciplinary field of systems and processes to extract information from data in many forms. It builds and modifies Artificial Intelligence Software’s to obtain information from huge data clusters and data sets. Data science covers a wide array of data-oriented technologies including SQL, Python, R, and Hadoop, etc. However, it also makes extensive use of statistical analysis, data visualization, distributed architecture, etc.
Data scientist may be an expert in experimental design, forecasting, modelling, statistical inference, or other things typically taught in statistics departments. Generally speaking though, the work product of a data scientist is not “p-values and confidence intervals” as academic statistics sometimes seems to suggest.
Machine Learning (ML): It is the ability of a computer system to learn from the environment and improve itself from experience without the need for any explicit programming. Machine learning focuses on enabling algorithms to learn from the data provided, gather insights and make predictions on previously unanalyzed data using the information gathered. Machine learning can be performed using multiple approaches. The three basic models of machine learning are supervised, unsupervised and reinforcement learning.
Artificial intelligence (AI): AI is a subfield of computer science that was created in the 1960s and it was (is) concerned with solving tasks that are easy for humans, but hard for computers. In particular, a so-called Strong AI would be a system that can do anything a human can (perhaps without purely physical things). This is fairly generic, and includes all kinds of tasks, such as planning, moving around in the world, recognizing objects and sounds, speaking, translating, performing social or business transactions, creative work (making art or poetry), etc.(or)
Artificial intelligence refers to the simulation of a human brain function by machines. This is achieved by creating an artificial neural network that can show human intelligence. Artificial intelligence is classified into two parts, general AI and Narrow AI. General AI refers to making machines intelligent in a wide array of activities that involve thinking and reasoning. Narrow AI, on the other hand, involves the use of artificial intelligence for a very specific task.
Final my point of view: AI is a very wide term with applications ranging from robotics to text analysis. It is still a technology under evolution and there are arguments of whether we should be aiming for high-level AI or not. Machine learning is a subset of AI that focuses on a narrow range of activities. It is, in fact, the only real artificial intelligence with some applications in real-world problems.
Data science isn’t exactly a subset of machine learning but it uses ML to analyze data and make predictions about the future. It combines machine learning with other disciplines like big data analytics and cloud computing. Data science is a practical application of machine learning with a complete focus on solving real-world problems. (Source: newgenapps)